Python Source
UpdatedAdd our Python library to your project to send server-side events representing your audience’s activities. This library saves you the trouble of writing your own code to send events into Customer.io and other cloud-based destinations.
How it works
Our python library helps you record source events from your node-side code. Requests from your python app go to our servers, and we route your data to your destinations.
This library uses an internal queue so that your identify and track calls are non-blocking and fast. It also batches requests and flushes asynchronously to Customer.io’s servers.
Like our other libraries, you can log anonymous activity—track and page events—with an anonymousId. When you identify a person, you can pass the anonymousId and we’ll associate the anonymous activity with the identified person.
Getting Started
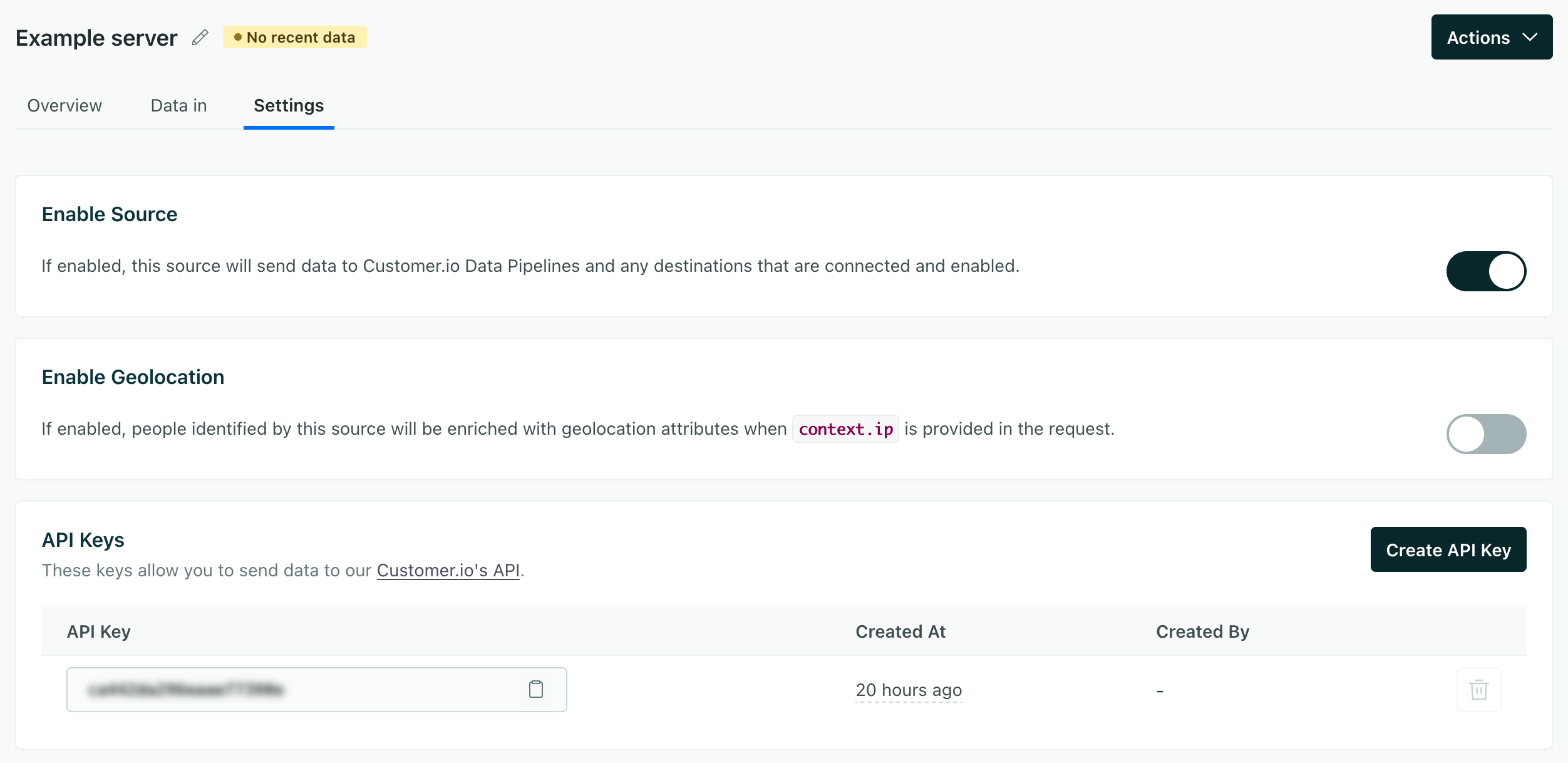
Go to the tab and click Sources.
Click Add Source and pick Python.
Give the source a Name and click Complete Setup. The name is simply a friendly name to help you find and recognize your source in Customer.io.
Install the python library. If you use a system to manage dependencies, you should pin the library to
1.Xto avoid breaking changes when we make updates.pip install customerio-cdp-analyticsImport the library in your app and set your
write_keybefore making anyanalytics. If you’re in our EU data center, you can also set thehostparameter tohttps://cdp-eu.customer.io.from customerio import analytics analytics.write_key = 'YOUR_WRITE_KEY' # If you're in our EU data center # analytics.host = 'https://cdp-eu.customer.io'
Now you’re ready to make calls to Customer.io!
The default initialization settings are production-ready and will queue individual analytics calls. A separate background thread is responsible for making the requests to Customer.io, so calls to the library won’t block your program’s execution.
You can send multiple sources
If you need to send data from multiple sources, you can initialize a new Client for each write_key!
If you’re in our EU data center
You’ll need to set the host parameter to our EU URL (https://cdp-eu.customer.io). Note that our EU regional endpoints account for the location of your data in Customer.io; they don’t account for the locations of your sources and destinations.
from customerio import analytics
analytics.write_key = 'YOUR_WRITE_KEY'
analytics.host = 'https://cdp-eu.customer.io'Enable automatic geolocation support
You can automatically geolocate people when you identify them and pass their IP addresses in the context.ip field in your identify requests. This helps you gather information about your audience’s location and time zone so you can schedule messages at the right times or send messages relevant to their communities.
If you’ve already set up your integration to capture IP addresses, and you’ve enabled the workspace-level Automatic Geolocation Data Collection setting, you can enable geolocation for your integration.
After you set up your integration, go to your integration’s Settings tab and turn on the Enable Geolocation setting.
Make sure you capture your users’ IP addresses
If you don’t set the context.ip in your requests, we won’t be able to capture geolocation data for your users. If our libraries infer the address as your server’s IP address, it’ll look like everyone is in the same location as your server.
Development settings
By default, the python library is set to queue and send requests directly to Customer.io. But, while you’re integrating this library, you should enable some settings to help you troubleshoot problems.
- Use
analytics.debugto log debugging information to the python logger - Set an
on_errorhandler to print the response you receive from our API.
def on_error(error, items):
print("An error occurred:", error)
analytics.debug = True
analytics.on_error = on_error
You can also prevent the library from sending data to Customer.io during testing. This can save you the trouble of cleaning out bogus data later.
analytics.send = False
Identify
The identify method tells us who the current website visitor is, and lets you assign unique traitsA key-value pair that you associate with a person or an object—like a person’s name, the date they were created in your workspace, or a company’s billing date etc. Use attributes to target people and personalize messages. to a person.
You should call identify when a user creates an account, logs in, etc. You can also call it again whenever a person’s traits change. We’ve shown a typical call with a traits object, but we’ve listed all the fields available in an identify call below.
You can send an identify call with an anonymousId and/or userId.
anonymousIdonly: This assigns traits to a person before you know who they are.userIdonly: Identifies a user and sets traits.- both
userIdandanonymousId: Associates the data sent in previous anonymouspage,track, andidentifycalls with the person you identify byuserId.
analytics.identify('f4ca124298', {
'email': 'cool.person@example.com',
'first_name': 'cool',
'last_name': 'person'
})
- anonymousId stringA unique substitute for a User ID in cases when you don’t have an absolutely unique identifier. Our libraries generate this value automatically to help you track people before they sign up, log in, provide their email, etc.
-
- active boolean
Whether a user is active.
This is usually used when you send an .identify() call to update the traits independently of when you’ve “last seen” a user.
- channel stringThe channel the event originated from.
Accepted values:
browser,server,mobile - ip stringThe user’s IP address. This isn’t captured by our libraries, but by our servers when we receive client-side events (like from our JavaScript source).
- locale stringThe locale string for the current user, e.g.
en-US. - userAgent stringThe user agent of the device making the request
-
- content string
- medium stringThe type of traffic a person/event originates from, like
email, orreferral. - name stringThe campaign name.
- source stringThe source of traffic—like the name of your email list, Facebook, Google, etc.
- term stringThe keyword term(s) a user came from.
- Additional UTM Parameters* string
-
- keywords array of [ strings ]A list/array of keywords describing the page’s content. The keywords are likely the same as, or similar to, the keywords you would find in an HTML
metatag for SEO purposes. This property is mainly used by content publishers that rely heavily on pageview tracking. This isn’t automatically collected. - name stringThe name of the page. Reserved for future use.
- path stringThe path portion of the page’s URL. Equivalent to the canonical
pathwhich defaults tolocation.pathnamefrom the DOM API. - referrer stringThe previous page’s full URL. Equivalent to
document.referrerfrom the DOM API. - search stringThe query string portion of the page’s URL. Equivalent to
location.searchfrom the DOM API. - title stringThe page’s title. Equivalent to
document.titlefrom the DOM API. - url stringA page’s full URL. We first look for the canonical URL. If the canonical URL is not provided, we’ll use
location.hreffrom the DOM API.
-
- Enabled/Disabled integrations* boolean
- timestamp string (date-time)The ISO-8601 timestamp when the event originally took place. This is mostly useful when you backfill data past events. If you’re not backfilling data, you can leave this field empty and we’ll use the current time or server time.
-
- createdAt string (date-time)We recommend that you pass date-time values as ISO 8601 date-time strings. We convert this value to fit destinations where appropriate.
- email stringA person’s email address. In some cases, you can pass an empty
userIdand we’ll use this value to identify a person. - Additional Traits* any typeTraits that you want to set on a person. These can take any JSON shape.
- userId stringThe unique identifier for a person. This value should be unique across systems, so you recognize the same person in your sources and destinations.
Track
The track method tells us about actions people take—the events people perform—on your site. Every track call represents an event.
You should track your audience’s activities with events both as performance indicators and so you can respond to your audience’s activities with campaignsCampaigns are automated workflows you set up to send people messages and perform other actions when they meet your criteria. in Journeys. For example, if your audience performs a Video Viewed or Item Purchased event, you might respond with other videos or products the person might enjoy.
You can send events with an anonymousId or a userId. Calls that you make with an anonymousId are associated with a userId when you identify someone by their userId.
Track calls require an event name describing what a person did. And they generally include a series of properties, providing additional information about the event. Beyond that, we’ve provided a complete schema for writable event fields below, and you can find more information in our API documentation.
analytics.track('f4ca124298', 'added_to_cart', {
'product': "shoes",
'revenue': 39.95,
'qty': 1
'size': 9
})
-
- active boolean
Whether a user is active.
This is usually used when you send an .identify() call to update the traits independently of when you’ve “last seen” a user.
- channel stringThe channel the event originated from.
Accepted values:
browser,server,mobile - ip stringThe user’s IP address. This isn’t captured by our libraries, but by our servers when we receive client-side events (like from our JavaScript source).
- locale stringThe locale string for the current user, e.g.
en-US. - userAgent stringThe user agent of the device making the request
-
- content string
- medium stringThe type of traffic a person/event originates from, like
email, orreferral. - name stringThe campaign name.
- source stringThe source of traffic—like the name of your email list, Facebook, Google, etc.
- term stringThe keyword term(s) a user came from.
- Additional UTM Parameters* string
-
- keywords array of [ strings ]A list/array of keywords describing the page’s content. The keywords are likely the same as, or similar to, the keywords you would find in an HTML
metatag for SEO purposes. This property is mainly used by content publishers that rely heavily on pageview tracking. This isn’t automatically collected. - name stringThe name of the page. Reserved for future use.
- path stringThe path portion of the page’s URL. Equivalent to the canonical
pathwhich defaults tolocation.pathnamefrom the DOM API. - referrer stringThe previous page’s full URL. Equivalent to
document.referrerfrom the DOM API. - search stringThe query string portion of the page’s URL. Equivalent to
location.searchfrom the DOM API. - title stringThe page’s title. Equivalent to
document.titlefrom the DOM API. - url stringA page’s full URL. We first look for the canonical URL. If the canonical URL is not provided, we’ll use
location.hreffrom the DOM API.
- event stringRequired The name of the event
-
- Enabled/Disabled integrations* boolean
-
- Event Properties* any typeAdditional properties that you want to capture in the event. These can take any JSON shape.
- timestamp string (date-time)The ISO-8601 timestamp when the event originally took place. This is mostly useful when you backfill data past events. If you’re not backfilling data, you can leave this field empty and we’ll use the current time or server time.
- userId stringRequired The unique identifier for a person. This value should be unique across systems, so you recognize the same person in your sources and destinations.
Deduplicate events
Generally, we’ll generate a message_id for each event you send to Customer.io. But, you can set your own message_id, which might be helpful if you need to deduplicate events.
We’ll accept the first instance of any operation with a given message_id and ignore any operations with the same message_id for the next 12 hours. The message_id is can be any string value, but we recommend a hash of the event data or a UUID/ULID to ensure that you don’t inadvertently deduplicate events.
If you backdate events, you’ll need to deduplicate them before you send them to Customer.io. We deduplicate the message_id within 12 hours from when we receive the event—not the timestamp on the event itself.
analytics.track(
user_id = 'f4ca124298',
event = 'added_to_cart',
properties = {
'product': "shoes",
'revenue': 39.95,
'qty': 1,
'size': 9,
},
message_id = 'message_id_here',
)Page
The Page method records page views on your website, along with optional extra information about the page a person visited.
If you’re using Customer.io’s client-side JavaScript library in combination with our python library, then the client side JavaScript library already captures page calls for you by default.
But, if you have a single page app or you don’t use our JavaScript client library on your website, you’ll need to send your own page calls.
-
- active boolean
Whether a user is active.
This is usually used when you send an .identify() call to update the traits independently of when you’ve “last seen” a user.
- channel stringThe channel the event originated from.
Accepted values:
browser,server,mobile - ip stringThe user’s IP address. This isn’t captured by our libraries, but by our servers when we receive client-side events (like from our JavaScript source).
- locale stringThe locale string for the current user, e.g.
en-US. - userAgent stringThe user agent of the device making the request
-
- content string
- medium stringThe type of traffic a person/event originates from, like
email, orreferral. - name stringThe campaign name.
- source stringThe source of traffic—like the name of your email list, Facebook, Google, etc.
- term stringThe keyword term(s) a user came from.
- Additional UTM Parameters* string
-
- keywords array of [ strings ]A list/array of keywords describing the page’s content. The keywords are likely the same as, or similar to, the keywords you would find in an HTML
metatag for SEO purposes. This property is mainly used by content publishers that rely heavily on pageview tracking. This isn’t automatically collected. - name stringThe name of the page. Reserved for future use.
- path stringThe path portion of the page’s URL. Equivalent to the canonical
pathwhich defaults tolocation.pathnamefrom the DOM API. - referrer stringThe previous page’s full URL. Equivalent to
document.referrerfrom the DOM API. - search stringThe query string portion of the page’s URL. Equivalent to
location.searchfrom the DOM API. - title stringThe page’s title. Equivalent to
document.titlefrom the DOM API. - url stringA page’s full URL. We first look for the canonical URL. If the canonical URL is not provided, we’ll use
location.hreffrom the DOM API.
-
- Enabled/Disabled integrations* boolean
- name stringRequired The name of the page.
-
- category stringThe category of the page. This might be useful if you have a single page routes or have a flattened URL structure.
- Page Properties* any typeAdditional properties tha tyou want to send with the page event. By default, we capture `url`, `title`, and stuff.
- timestamp string (date-time)The ISO-8601 timestamp when the event originally took place. This is mostly useful when you backfill data past events. If you’re not backfilling data, you can leave this field empty and we’ll use the current time or server time.
- userId stringRequired The unique identifier for a person. This value should be unique across systems, so you recognize the same person in your sources and destinations.
Group
The Group method associates an identified person with a group—like a company, organization, project, online class or any other collective noun you come up with for the same concept. In Customer.io Journeys, we call groups objectsAn object is a non-person entity that you can associate with one or more people—like a company, account, or online course..
Group calls are useful for integrations where you maintain relationships between people and larger organizations, like in Customer.io! In Customer.io Journeys, you can store groups as objectsAn object is a non-person entity that you can associate with one or more people—like a company, account, or online course., and trigger campaigns based on a person’s relationship to an object—like an account, online class, and so on.
Find more details about group, including the group payload, in our API spec.
analytics.group('user_id', 'group_id', {
'name': 'Initech',
'domain': 'Accounting Software'
})
Include objectTypeId when you send data to Customer.io
Customer.io supports different kinds of groups (called objectsAn object is a non-person entity that you can associate with one or more people—like a company, account, or online course.) where each object has an object type represented by an incrementing integer beginning at 1. If you send group calls to Customer.io, you should include the object type ID or we’ll assume that the object type is 1.
-
- active boolean
Whether a user is active.
This is usually used when you send an .identify() call to update the traits independently of when you’ve “last seen” a user.
- channel stringThe channel the event originated from.
Accepted values:
browser,server,mobile - ip stringThe user’s IP address. This isn’t captured by our libraries, but by our servers when we receive client-side events (like from our JavaScript source).
- locale stringThe locale string for the current user, e.g.
en-US. - userAgent stringThe user agent of the device making the request
-
- content string
- medium stringThe type of traffic a person/event originates from, like
email, orreferral. - name stringThe campaign name.
- source stringThe source of traffic—like the name of your email list, Facebook, Google, etc.
- term stringThe keyword term(s) a user came from.
- Additional UTM Parameters* string
-
- keywords array of [ strings ]A list/array of keywords describing the page’s content. The keywords are likely the same as, or similar to, the keywords you would find in an HTML
metatag for SEO purposes. This property is mainly used by content publishers that rely heavily on pageview tracking. This isn’t automatically collected. - name stringThe name of the page. Reserved for future use.
- path stringThe path portion of the page’s URL. Equivalent to the canonical
pathwhich defaults tolocation.pathnamefrom the DOM API. - referrer stringThe previous page’s full URL. Equivalent to
document.referrerfrom the DOM API. - search stringThe query string portion of the page’s URL. Equivalent to
location.searchfrom the DOM API. - title stringThe page’s title. Equivalent to
document.titlefrom the DOM API. - url stringA page’s full URL. We first look for the canonical URL. If the canonical URL is not provided, we’ll use
location.hreffrom the DOM API.
- groupId stringRequired ID of the group
-
- Enabled/Disabled integrations* boolean
- objectTypeId stringIf you use Customer.io Journeys as a destination, this value is the type of group/object your group belongs to; object type IDs are stringified integers. If you don’t include this value, we assume the object type ID is
1. See objects in Customer.io Journeys for more information. - timestamp string (date-time)The ISO-8601 timestamp when the event originally took place. This is mostly useful when you backfill data past events. If you’re not backfilling data, you can leave this field empty and we’ll use the current time or server time.
-
- object_type_id stringIf you use Customer.io Journeys as a destination, this value is the type of group/object your group belongs to; object type IDs are stringified integers. If you don’t include this value, we assume the object type ID is
1. See objects in Customer.io Journeys for more information. - Group Traits* any typeAdditional traits you want to associate with this group.
- userId stringThe unique identifier for a person. This value should be unique across systems, so you recognize the same person in your sources and destinations.
Alias
The Alias method combines two previously unassociated user identities. Some integrations automatically reconcile profiles with different identifiers based on whether you send anonymousId, userId, or another trait that the integration expects to be unique. But for integrations that don’t, you may need to send alias requests to do this.
In general, you won’t need to use the alias call; we try to handle user identification gracefully so you don’t need to merge profiles. But you may need to send alias calls to manage user identities in some data-out integrations.
For example, in Mixpanel it’s used to associate an anonymous user with an identified user once they sign up.
analytics.alias(previous_id, user_id)
Here’s how you might use the alias call. In this case, we start with an anonymous_user and switch to an email address when a person provides their userId.
# the anonymous user does actions under an anonymous ID
analytics.track('92734232-2342423423-973945', 'Anonymous Event')
# the anonymous user signs up and is aliased to their new user ID
analytics.alias('92734232-2342423423-973945', '1234')
# the user is identified
analytics.identify('1234', { 'plan': 'Free' })
# the identified user does actions
analytics.track('1234', 'Identified Action')
- previousId stringRequired The userId that you want to merge into the canonical profile.
- userId stringRequired The userId that you want to keep. This is required if you haven’t already identified someone with one of our web or server-side libraries.
Configuration and Library Options
If you want to change the library’s default settings want to send data to multiple sources, you can create your own client(s). Remember that each client runs a separate background thread, so you won’t want to create new clients on every request.
from analytics import Client
Client('YOUR_WRITE_KEY', debug=True, on_error=on_error, send=True,
max_queue_size=100000, upload_interval=5, upload_size=500, gzip=True)
| Field | Description |
|---|---|
debug bool | Set True to enable verbose logging, False by default. |
send bool | Set False to avoid sending data to Customer.io, True by default. |
on_error function | Set an error handler to be called whenever errors occur. |
max_queue_size int | The maximum number of elements allowed in the queue. Hitting the max queue size means you’re identifying / tracking faster than you can flush. If this happens, let us know! |
upload_interval float | The frequency, in seconds, of sends to Customer.io. Default value is 0.5. |
upload_size int | The number of items per batch upload. Default value is 100. |
gzip bool | Set True to compress data with gzip before sending, False by default. |
Selecting Destinations
You can pass an integrations object to alias, group, identify, page and track calls that lets you turn certain destinations on or off. By default all destinations are enabled. Passing false for an integration disables the call to that destination.
You might want to do this for things like alias calls, which aren’t supported by all destinations.
In this case, Customer.io specifies the track to only go to Vero. All: false disables all destinations except the ones you explicitly specify.
analytics.track('user_id', 'Membership Upgraded', integrations={
'All': False,
'Mixpanel': True,
'Google Analytics': False
})
Destination flags are case sensitive. You’ll find each integration’s name at the top of each integration’s page in our documentation.
You can filter track calls on the source’s Schema tab
We recommend that you filter events in our UI if you can. It’s easier than writing code, and you can update your source or make changes to your filters without involving developers!
Backfilling historical data
You can backfill data by adding a timestamp to your calls. This can be helpful if you’ve just switched to Customer.io.
You can only do this for destinations that accept timestamped data—most analytics tools like Mixpanel and Amplitude do. The notable destination that doesn’t support timestamped data is Google Analytics.
import datetime
from dateutil.tz import tzutc
timestamp = datetime.datetime(2538, 10, 17, 0, 0, 0, 0, tzinfo=tzutc())
analytics.track('019mr8mf4r', 'started_class', {
'class': 'How to Use CDP'
}, timestamp=timestamp)
Leave out the timestamp if you’re tracking real-time events
If you’re only tracking things as they happen, you can leave the timestamp out of your calls and we’ll timestamp requests for you.
Time zones in Python
Python’s datetime module supports two types of date and time objects: naive objects without time zone information, and aware objects that include time zones. By default, newly created datetime objects are naive. Make sure that you use time zone aware objects when you import data so that you send time zone information correctly.
We created an aware datetime object in the previous section using the tzinfo argument to the datetime constructor. If you omitted this argument, we would not pass time zone info:
>>> naive = datetime.datetime(2015, 1, 5, 0, 0, 0, 0)
>>> aware = datetime.datetime(2015, 1, 5, 0, 0, 0, 0, tzinfo=tzutc())
>>> naive.isoformat()
'2015-01-05T00:00:00'
>>> aware.isoformat()
'2015-01-05T00:00:00+00:00'
If you have an ISO format timestamp string that contains time zone information, dateutil.parser can create aware datetime objects.
>>> import dateutil.parser
>>> dateutil.parser.parse('2012-10-17T18:58:57.911Z')
datetime.datetime(2012, 10, 17, 18, 58, 57, 911000, tzinfo=tzutc())
>>> dateutil.parser.parse('2016-06-06T01:46:33.939388+00:00')
datetime.datetime(2016, 6, 6, 1, 46, 33, 939388, tzinfo=tzutc())
>>> dateutil.parser.parse('2016-06-06T01:46:33.939388+07:00')
datetime.datetime(2016, 6, 6, 1, 46, 33, 939388, tzinfo=tzoffset(None, 25200))
>>> dateutil.parser.parse('2016-06-06T01:46:33.939388-07:00')
datetime.datetime(2016, 6, 6, 1, 46, 33, 939388, tzinfo=tzoffset(None, -25200))
If you find yourself with a naive object, and know what time zone it should be in, you can also use pytz to create an aware datetime object from the naive one.
>>> import datetime
>>> import pytz
>>> naive = datetime.datetime.now()
>>> aware = pytz.timezone('US/Pacific').localize(naive)
>>> naive.isoformat()
'2016-06-05T21:52:14.499635'
>>> aware.isoformat()
'2016-06-05T21:52:14.499635-07:00'
The pytz documentation contains additional information on time zone usage, and can help you handle edge cases.
Batching
Our libraries are built to support high performance environments. It’s safe to use this library on a web server that serves hundreds of requests per second.
But every method you invoke does not result in an HTTP request. Instead, we queue requests in memory and then flush them in batches, which allows for more efficient operation.
By default, our Python source library flushes:
- every 100 messages (control with
upload_size) - if 0.5 seconds has passed since the last flush (control with
upload_interval)
There is a maximum of 500KB per batch request and 32KB per call.
What happens if there are too many messages?
If our python module can’t flush calls faster than it’s receiving them, it’ll simply stop accepting requests. This means your program will never crash because of a backed up analytics queue. The default max_queue_size is 10000.
Flush events on demand
You can flush your queue on demand. For example, at the end of your program, you’ll want to flush to make sure there’s nothing left in the queue. Just call the flush method.
analytics.flush()
This method blocks the calling thread until there the message queue is empty. You’ll want to use it as part of your cleanup scripts and avoid using it as part of the request lifecycle.
How do I gzip requests?
You can compress batched requests before you send them to Customer.io by setting the gzip argument when constructing your Client.
from analytics import Client
Client('YOUR_WRITE_KEY', gzip=True)
Detecting errors
You can listen to events on failed flush attempts.
def on_error(error, items):
print('Failure', error)
analytics.on_error = on_error
Logging
Our library uses the standard python logging module. By default, logging is enabled and set at the WARNING level. If you want more verbose logs, you can set a different log_level:
import logging
logging.getLogger('customerio').setLevel('DEBUG')

