Differences between the Pipelines and Track APIs
UpdatedA comprehensive comparison of the Track API and Pipelines API to help you understand when and how to use them.
TL;DR: Which API should I use?
We recommend that you use the Pipelines API unless you send data to Customer.io through a customer data platform (CDP) like Segment or Rudderstack. The Pipelines API is newer and includes support for newer Customer.io features like geolocation.
General differences
We have two APIs to help you get data into Customer.io: the Track API and the Pipelines API. If you’re new to Customer.io: most of our libraries and SDKs are based on the Pipelines API; it’s what you’ll use for most integrations.
If you’re migrating from an earlier integration that used the Track API, this page can help you understand the differences between your track-based integration and our Pipelines API.
The Pipelines API is based on customer data platform (CDP) APIs like Segment or Rudderstack. It’s a bit more generic than the Track API, and that means you may need to map some concepts from the Pipelines API to their equivalents in Customer.io. But, most of our integrations are built on this API. Understanding it can help you better support your integrations.
The Track API is purpose-built for Customer.io, but libraries built on it don’t support as many features as our newer, Pipelines-based integrations. While there are two versions of the Track API, we typically mean the track v1 API when we talk about The Track API because the v2 API isn’t used in any of our libraries and rarely used in libraries built by third parties; it’s much more common that you’d encounter the v1 API.
| Feature | Track API | Pipelines API |
|---|---|---|
| Base URL | track.customer.io/api | cdp.customer.io |
| Version | v1, v2 (v2 is not used in any of our libraries) | v1 |
| Authentication | Basic Site ID:API Key | Basic API Key: |
| Delete calls | DELETE method | Use semantic events |
| Person ID | {identifier} in path (v1 API); can be id or email | userId in request body; can be id or email |
| Profile Attributes | Direct key-value pairs in identify calls | traits object in identify calls |
| Event name | name parameter | event parameter |
| Event properties | data object | properties object |
| Timestamps | Unix timestamps (integers in seconds) | ISO 8601 strings (down to milliseconds) |
| Object support | v2 version of the Track API | /group call |
| Request Limit | 32 KB single (v1/v2), 500 KB batch (v2 only) | 64 KB single, 1 MB batch |
JavaScript snippets
While we typically offer integrations based on our Pipelines API, we have two different JavaScript snippets—one based on the Pipelines API and one based on the Track API. We recommend the snippet based on the Pipelines API because it offers features that aren’t available for the classic, track API-based snippet. You’ll find the recommended, Pipelines-based JavaScript snippet in our integrations catalog.
If you have an older integration, you might be using our Track-based JavaScript snippet. It’s no longer available in our integrations catalog, but we have code samples in our legacy JavaScript documentation.
| Pipelines-based snippet | Track-based snippet | |
|---|---|---|
t-src | https://cdp.customer.io/v1/analytics-js/snippet/ | https://track.customer.io/v1/analytics-js/snippet/ |
| Authentication | analytics.load("YOUR_WRITE_KEY"); | t.setAttribute('data-site-id', 'YOUR_SITE_ID'); |
| Invoked with | analytics or cioanalytics | _cio |
| Supports anonymous in-app messaging | ||
| Supports objects | requires a work-around | |
| Supports batching |
Get API keys
While both APIs use basic authentication, you’ll get and use API keys differently for the two APIs.
The Pipelines API uses basic authentication with a single key rather than a username and password. When you use the API directly, you’ll enter the key as the username and a blank password.
The Track API uses a traditional basic authentication scheme with a site ID and API key as the username and password respectively.
Get a Pipelines API Key
- Go to Data & Integrations > Integrations and click Add Integration.
- Find the Customer.io API integration.
- Give the integration a name. The name helps you find and differentiate between different API credentials; you might name them for users, environments, or the services you use them for.
- Use the key to send a successful test call. You can’t save your credentials until you’ve sent a successful test:
curl --request POST \ --url https://cdp.customer.io/v1/identify \ --header 'Authorization: Basic <your key here>'\ --header 'content-type: application/json' \ -d ' { "userId": "97980cfea0067", "traits": { "name": "Cool Person", "email": "cool.person@example.com" } }' - Click Complete Setup.
Get Track API credentials
Click Create Track API Key.
Give your credentials a name and select the workspace you want to use them in. The name helps you find and differentiate between different API credentials; you might name them for users, environments, or the services you use them for.
Click Create Track API Key one last time, and you’ll have your credentials. You’ll use your Site ID and API Key as a username and password for basic authorization when you call our API. You can use these credentials with partners like Segment.
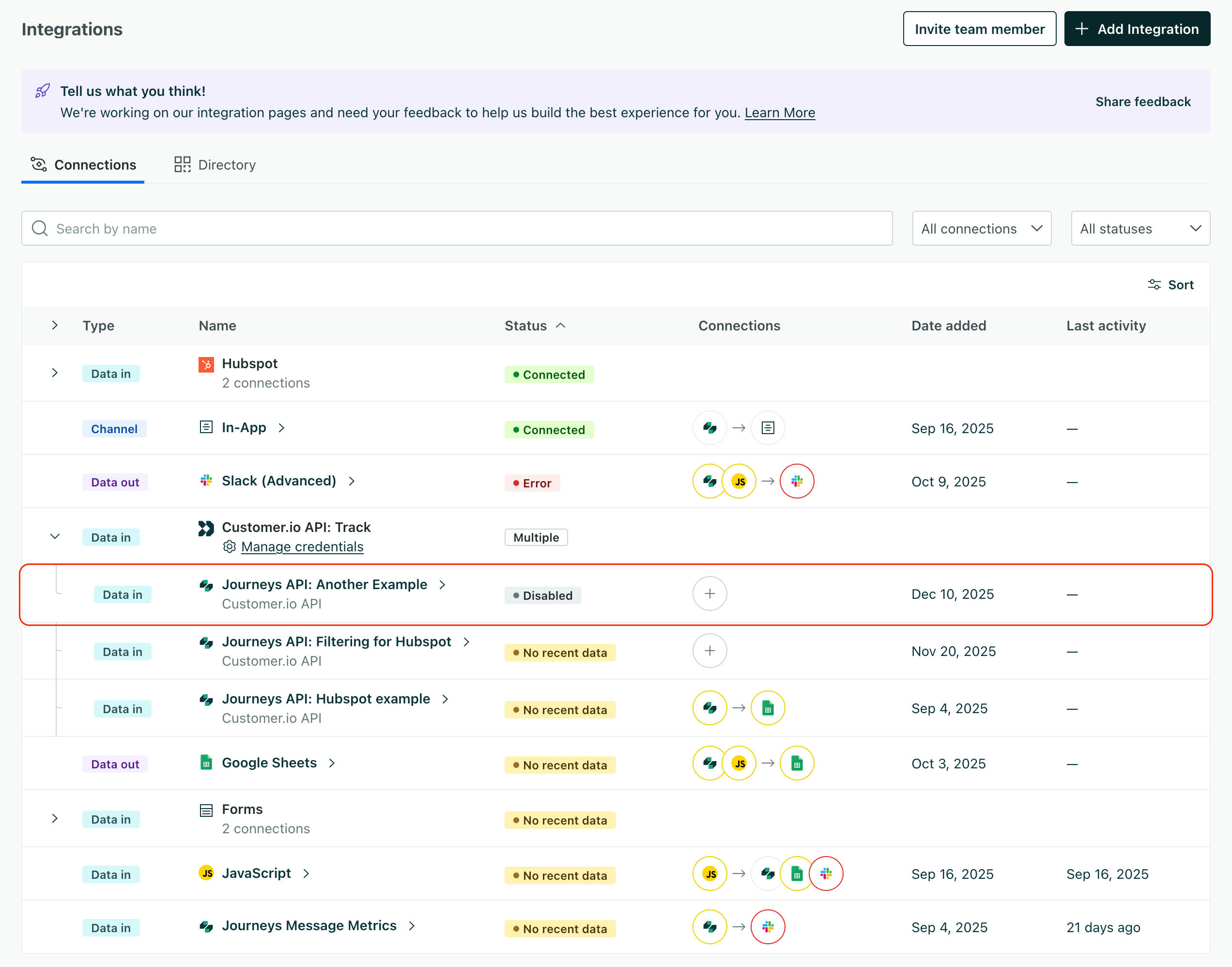
If you go to the Data & Integrations > Integrations page, you’ll see your new credentials listed under Customer.io API: Track as Journeys API: <credential name>.
Two versions of the Track API
The Track API has two versions: v1 and v2. While we discuss the v2 API in a few places on this page, and it can be useful if you write your own integration, it isn’t used in any of our libraries.
Most of the time, when we talk about The Track API, we’re talking about the v1 API. It was much more commonly used in our older integrations and is still in use in some third-party integrations. For example, if you integrate with Customer.io using Segment, Segment sends data to Customer.io using the Track v1 API.
The major differences between the v1 and v2 APIs are that the v2 API only has two endpoints: entity and batch and determines what to do based on the type and action in the payload. The type represents the thing you want to work with and the action is what you want to do with it. Unlike our v1 API, the v2 API supports objects and relationships natively.
Deleting data
The Track API supports DELETE calls to remove data. The Pipelines API does not; it only contains POST calls to add and update data.
To delete data with the Pipelines API, you’ll send a POST to the /track endpoint with a specific event name—we call these “semantic events.” For example, you can send a POST to the /track endpoint with the event name User Deleted to remove a person from Customer.io.
See Semantic Events for a list of the semantic events you can use with Customer.io and our Pipelines API.
Identifying people: id and userId
In Customer.io, people have an id and an email address. You can use either to identify them, but they appear differently in our APIs.
When you use the Track v1 API, you identify people by their id or email address as a part of the URL path.
For the Pipelines API, you pass a userId in your payloads. This value can be an id or an email address and Customer.io will automatically handle it as the correct identifier. If you need to pass both, you’d pass the userId and a traits.email attribute to store the email address.
| Track API | Pipelines API |
|---|---|
PUT /api/v1/customers/user123 | POST /v1/identify/ |
| |
Attributes in identify calls
The Track API treats all values in the payload of an identify call as attributes.
The Pipelines API uses a traits object to pass attributes. This is because the Pipelines API supports different objects in its payload (like context and integrations, etc.)
| Track API | Pipelines API |
|---|---|
PUT https://track.customer.io/api/v1/customers/user123 | POST https://cdp.customer.io/v1/identify/ |
| |
Tracking events
The Track v1 API includes the identifier for the person performing the event in the URL path (user123 in the example below), has a name parameter to pass the event name, and includes a data object to pass event properties.
The Pipelines API expects the userId in the payload, uses the event parameter to pass the event name, and includes a properties object to pass event properties.
| Track API | Pipelines API |
|---|---|
PUT https://track.customer.io/api/v1/customers/user123/events | POST https://cdp.customer.io/v1/track |
| |
Managing objects (groups)
The Pipelines API is the preferred way to support objectsAn object is a non-person entity that you can associate with one or more people—like a company, account, or online course. because it has a native concept of objects and a more consistent structure with the /group endpoint.
To support objects with the Track API, we suggest you use the v2 version of the Track API. But, if you’re using any of our libraries based on the Track API—all of which use v1—you’ll need to support objects as a part of your identify calls. You cannot delete objects with the Track v1 API.
Pipelines API (Recommended)
The Pipelines API has the most conventional payload for objects. You’ll pass a groupId representing the object, traits representing the object’s attributes, and a traits.relationship_traits object representing the relationship between the object and the person.
POST https://cdp.customer.io/v1/group/
{
"userId": "user123",
"groupId": "group123",
"traits": {
"object_type_id": "1",
"account_name": "Acme",
"account_type": "enterprise",
"relationship_traits": {
"is_admin": true,
"position": "account manager"
}
}
}Track API v2
The Track v2 API has a more conventional payload for objects. While this is an easy way to support objects, none of our libraries rely on this API, so you’ll only use it when you call the API directly.
The v2 API only has entity and batch endpoints. To support objects, you’ll set the type in the payload to object to work with objects.
POST https://track.customer.io/v2/entity/
{
"identifiers": {
"object_type_id": "1",
"object_id": "group123"
},
"type": "object",
"action": "identify",
"attributes": {
"account_name": "Acme",
"account_type": "enterprise"
},
"cio_relationships": [
{
"identifiers": {
"id": "user123"
},
"relationship_attributes": {
"is_admin": true,
"position": "account manager"
}
}
]
}Track API v1
The track v1 API doesn’t support objects, but you can pass a cio_relationships object to your identify calls to add and remove objects.
If the object_id in your request doesn’t exist, we’ll create it. While you can create and relate objects to people with this action, you can’t add attributes to an object with this action. You’d need to use one of our other APIs to do that.
PUT https://track.customer.io/v1/customers/user123/
{
"first_name": "Bob",
"plan": "basic",
"cio_relationships": {
"action": "add_relationships",
"relationships": [
{
"identifiers": {
"object_type_id": "1",
"object_id": "group123"
},
"relationship_attributes": {
"is_admin": true,
"position": "account manager"
}
}
]
}
}Timestamps
By default, the Pipelines API uses ISO 8601 timestamps (down to milliseconds), like 2023-04-26T13:42:19.722Z. The Track API, by comparison, uses Unix timestamps (in seconds), like 1361205308.
Customer.io typically relies on Unix timestamps for things like segmentA group of people who match a series of conditions. People enter and exit the segment automatically when they match or stop matching conditions. conditions where you might do time-based calculations. For example, if you check that an attribute is a timestamp in a segment, it will evaluate to true if the value is a Unix timestamp and false if it’s an ISO timestamp.
Most of the time, you don’t need to worry about this difference. By default, Customer.io converts ISO-8601 timestamps that come from the Pipelines API (and associated libraries) to Unix timestamps to support things you might do in Customer.io. But this distinction can be important if you need to store and manipulate timestamps in your own code.
Why does the Pipelines API use ISO 8601 timestamps when Customer.io generally expects Unix timestamps? Because ISO 8601 timestamps are common to many other platforms, and the Pipelines API is designed like a traditional customer data platform (CDP)—where you can send data to both Customer.io and other destinations.
The Pipelines API also includes additional timestamps—fields like receivedAt, sentAt, and originalTimestamp.
| Track API | Pipelines API |
|---|---|
| Unix timestamp (seconds) | ISO 8601 format |
| |
The Pipelines API captures context and integrations
Because the Pipelines API is based off of traditional customer data platforms (CDPs) like Segment, it has reserved objects for context and integrations. The context object contains information about the event, like the IP address and user agent. The integrations object provides a way to determine which destinations you want to send your data to.
The Pipelines API has lax and strict modes
The Track API automatically validates certain aspects of requests—like the presence of required fields and the size of the request body.
The Pipelines API does not do this validation by default. Instead, it returns a 200 response for almost everything and logs errors in Customer.io. But you can enable the same validation available on the Track API by setting the X-Strict-Mode header to 1.
Pipelines validation modes
| Error Type | Strict Mode (X-Strict-Mode: 1) | Non-Strict Mode (default) |
|---|---|---|
| Authentication errors | Return HTTP 401/400 with error details | Logged but return HTTP 200 success |
| Content encoding errors (invalid gzip/deflate) | Return HTTP 400 with specific error messages | Logged but return HTTP 200 success |
| Request size violations (>32KB) | Return HTTP 400 with size limit details | Logged but return HTTP 200 success |
| JSON validation failures | Return HTTP 400 with validation error details | Logged but return HTTP 200 success |
| Missing required fields | Return HTTP 400 with field-specific error messages | Logged but return HTTP 200 success |
Required fields by request type
When using strict mode, the following fields are validated. If your payload doesn’t include these fields, it’ll fail with a 400 error.
- Identify, Track, Page, Screen, and Alias calls require at least one of
userIdoranonymousId. - Track calls require an
eventname. - Group calls require a
groupId. - Alias calls require a
previousId.
Maximum request sizes
The Track API has a 32 KB limit for single requests and a 500 KB limit for batch requests—which are only available in the v2/batch endpoint for the Track API.
The Pipelines API has a 64 KB limit for single requests and a 1 MB limit for batch requests.

