Azure blob storage
PremiumThis feature is available for Premium plans. EnterpriseThis feature is available for Enterprise plans. UpdatedSend Customer.io data about messages, people, metrics, etc to Microsoft Azure Blob Storage. From here, you can ingest your data into the data warehouse of your choosing. This integration exports files up to every 15 minutes, helping you keep up to date on your audience’s message activities.
We have two integrations!
How it works
This integration exports individual parquet files for Deliveries, Metrics, Subjects, Outputs, Content, People, and Attributes to your storage bucket. Each parquet file contains data that changed since the last export.
Once the parquet files are in your storage bucket, you can import them into data platforms like Fivetran or data warehouses like Redshift, BigQuery, and Snowflake.
Note that this integration only publishes parquet files to your storage bucket. You must set your data warehouse to ingest this data. There are many approaches to ingesting data, but it typically requires a COPY command to load the parquet files from your bucket. After you load parquet files, you should set them to expire to delete them automatically.
We attempt to export parquet files every 15 minutes, though actual sync intervals and processing times may vary. When syncing large data sets, or Customer.io experiences a high volume of concurrent sync operations, it can take up to several hours to process and export data. This feature is not intended to sync data in real time.
before next sync end
Your initial sync includes historical data
The initial export vs incremental exports
Your initial sync is a set of files containing historical data to represent your workspace’s current state. Subsequent sync files contain changesets.
- Metrics: The initial metrics sync is broken up into files with two sequence numbers, as follows.
<name>_v5_<workspace_id>_<sequence1>_<sequence2>. - Attributes: The initial Attributes sync includes a list of profiles and their current attributes. Subsequent files will only contain attribute changes, with one change per row.
- Events: The initial events sync includes up to 30 days of past events. Subsequent files contain events since the previous sync interval. We cannot export events older than 30 days.
already enabled?} c-->|yes|d[send changes since last sync] c-->|no|e{was the file
ever enabled?} e-->|yes|f[send changeset since
file was disabled] e-->|no|g[send all history]
For example, let’s say you’ve enabled the Attributes export. We will attempt to sync your data to your storage bucket every 15 minutes:
- 12:00pm We sync your Attributes Schema for the first time. This includes a list of profiles and their current attributes.
- 12:05pm User1’s email is updated to company-email@example.com.
- 12:10pm User1’s email is updated to personal-email@example.com.
- 12:15 We sync your data again. In this export, you would only see attribute changes, with one change per row. User1 would have one row dedicated to his email changing.
Requirements
If you use a firewall or an allowlist, you must allow the following IP addresses to support traffic from Customer.io. Make sure you use the correct IP addresses for your account region.
| US Region | EU Region |
|---|---|
| 34.71.192.245 | 34.118.255.179 |
| 35.188.196.183 | 34.76.143.229 |
| 104.198.177.219 | 34.78.91.47 |
| 35.184.88.76 | 35.187.55.80 |
| 34.72.101.57 | 104.199.99.65 |
| 34.123.199.33 | 34.76.81.2 |
| 35.222.137.61 | 34.77.146.181 |
| 34.68.113.63 | 34.140.234.108 |
| 35.240.84.170 | |
| 35.195.54.15 | |
| 34.38.105.52 | |
| 104.155.66.230 | |
| 34.76.119.61 | |
| 34.140.67.73 | |
| 34.78.74.81 |
Do you use other Customer.io features?
Set up an Azure Blob Storage integration
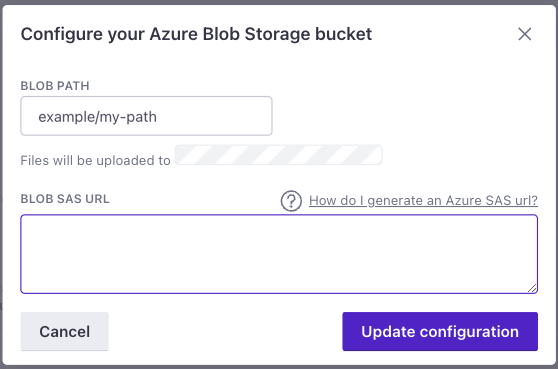
As a part of this process, you’ll create an Access policy and a Shared Access Signature (SAS) URL. The Shared Access Signature grants Customer.io access to your Azure blob container, but typically has a limited expiration date. Before you generate a SAS URL, you’ll create the Access policy (with read, write, add, create, and list permissions) that lets you set a longer expiration date for your SAS URL and provides a way to revoke the token later, if you decide to shut off this integration for any reason.
You must generate an SAS URL for a container, not a storage account!
Please follow the steps below to generate an SAS URL for a specific container in your Azure Blob Storage account. You can’t use a SAS URL for the storage account with Customer.io.
Login to your Azure account, go to Storage browser, and select Blob Containers.
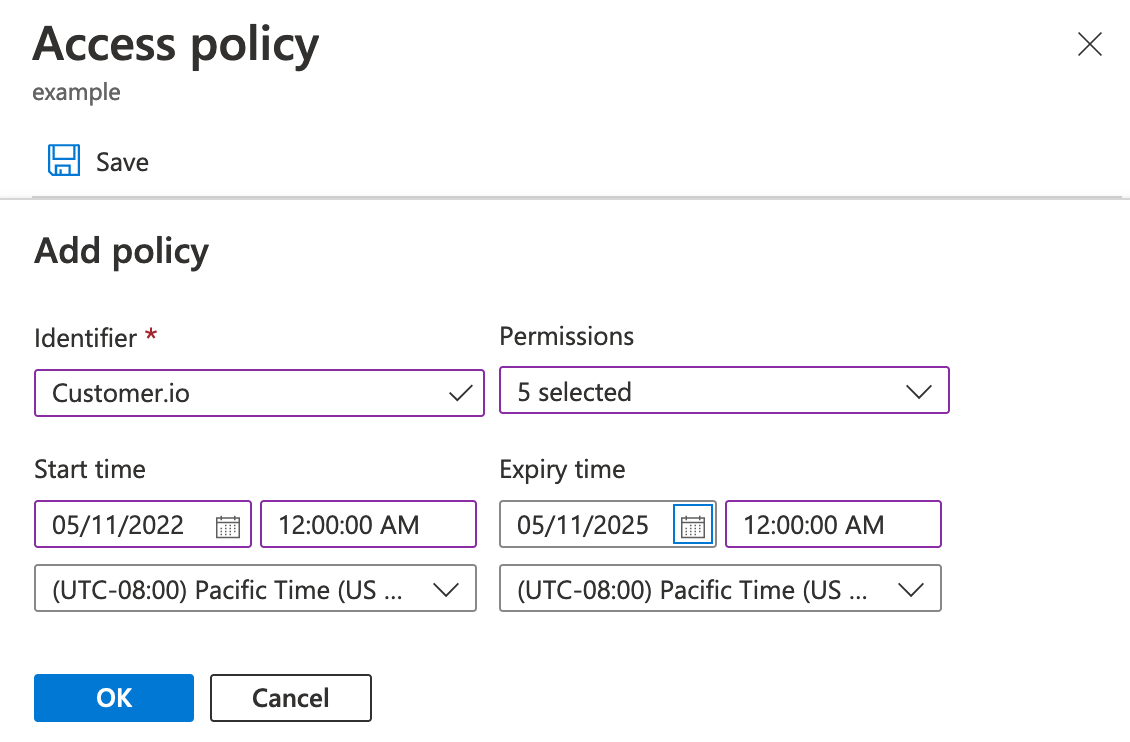
Right click the container you want to export Customer.io data to, and select Access policy to create a policy allowing you to create a SAS URL with a long expiry date.
- Click Add policy and set an Identifier for the policy. This is just the name of the access policy that you’ll use in later steps.
- Click Permissions and select read, write, add, create, and list.
- Set the Start time to the current date.
- Set the Expiry time to a date well into the future.
- Click OK and then click Save.
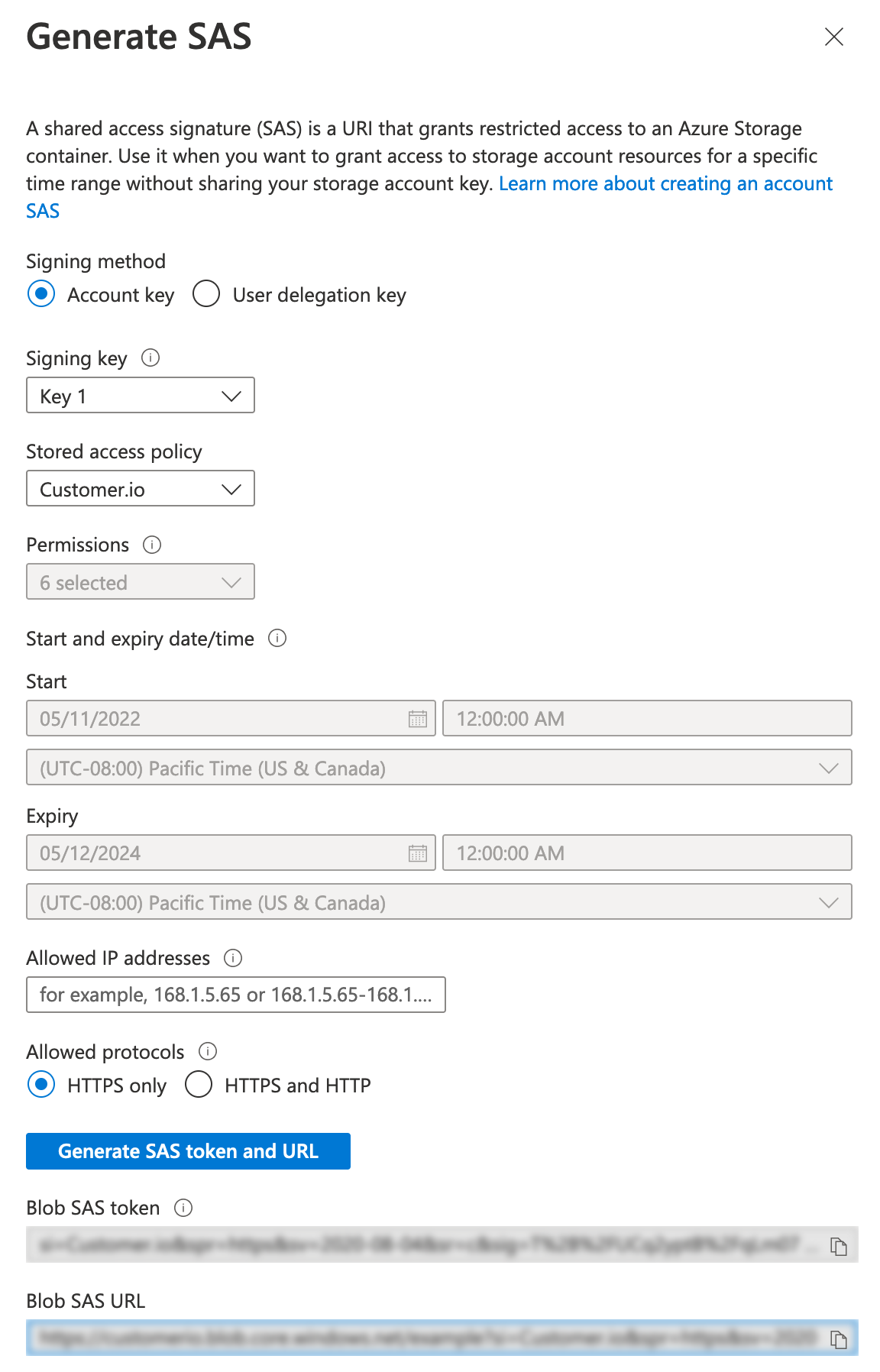
Right click the container again and select Generate SAS to generate the URL that Customer.io will use to access your Azure bucket.
- Select the Stored access policy you created in previous steps.
- (Optional) List Customer.io’s IP addresses under Allowed IP addresses to provide an extra layer of security for your SAS URL.
- Click Generate SAS token and URL and copy the URL. When you close the dialog, you won’t be able to access the token or URL again, so make sure that you copy the URL. You’ll need it in later steps.
Go to Customer.io and select Integrations > Azure Blob Storage.
Click Sync your Azure Blob Storage bucket.
Enter the Blob Path: this is the directory in the blob where you want to deposit parquet files with each sync. If you don’t provide a path, we’ll deposit files in the root of the blob. If the path doesn’t already exist, clicking “Validate & Select Data” will create a new blob storage path.
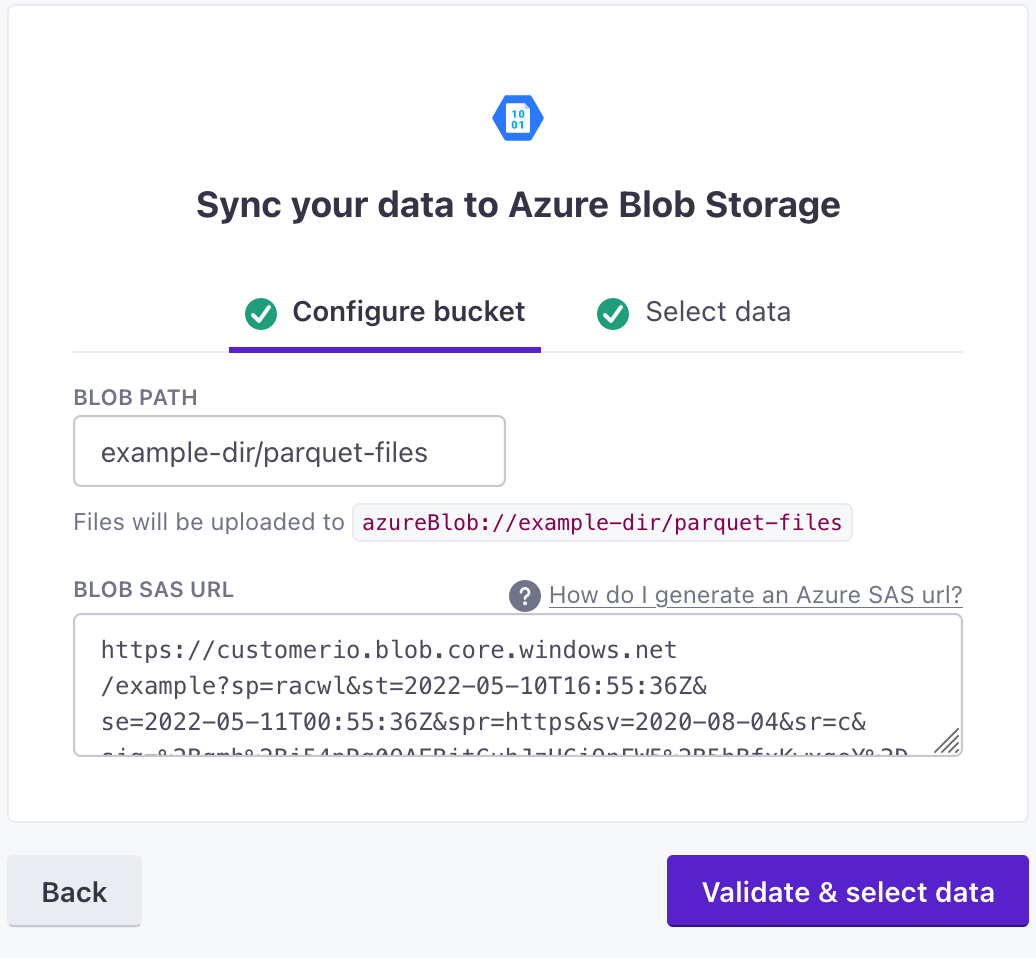
Paste your Blob SAS URL in the appropriate box and click Validate & select data.
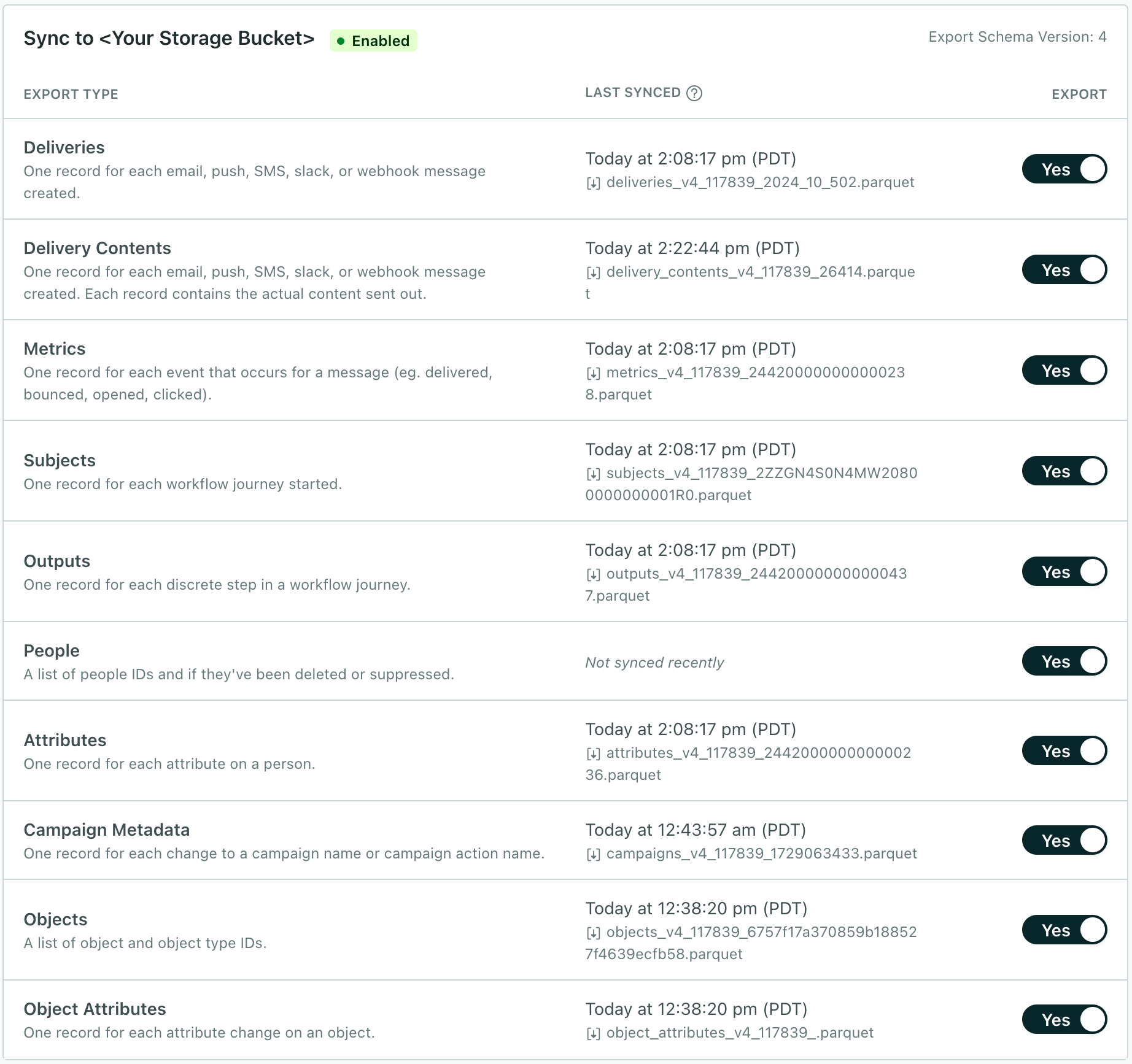
Select the data types that you want to export from Customer.io to your bucket. By default, we export all data types, but you can disable the types that you aren’t interested in.
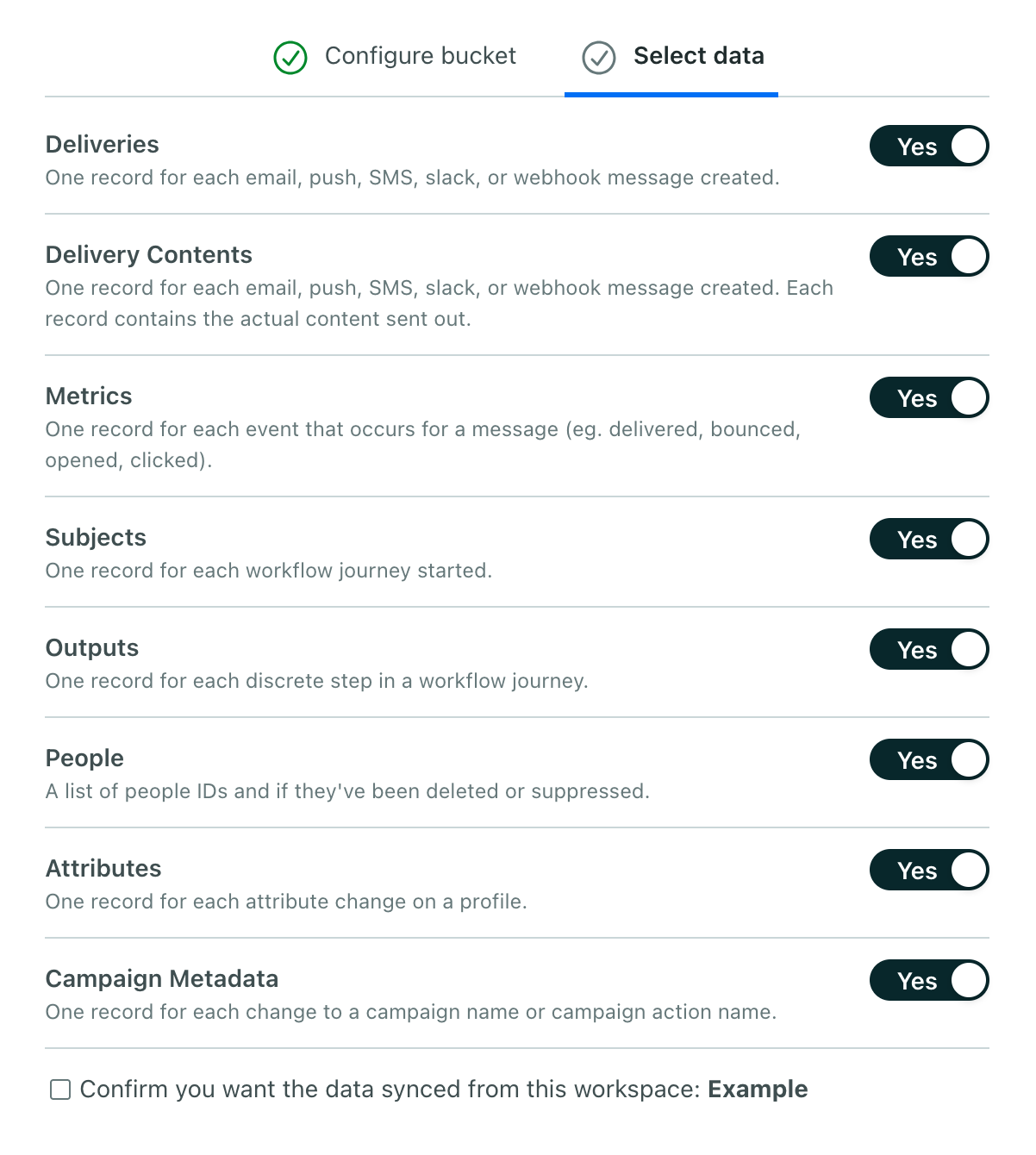
Click Create and sync data.
Pausing and resuming your sync
You can turn off files you no longer want to receive, or pause them momentarily as you update your integration, and turn them back on. When you turn a file schema on, we send files to catch you up from the last export.If you haven’t exported a particular file before—the file was never “on”—the initial sync contains your historical data.
You can also disable your entire sync, in which case we’ll quit sending files all together. When you enable your sync again, we send all of your historical data as if you’re starting a new integration. Before you disable a sync, consider if you simply want to disable individual files and resume them later.
Delete old sync files before you re-enable a sync
Before you resume a sync that you previously disabled, you should clear any old files from your storage bucket so that there’s no confusion between your old files and the files we send with the re-enabled sync.
Disabling and enabling individual export files
- Go to Data & Integrations > Integrations and select Azure Blob Storage.
- Select the files you want to turn on or off.
When you enable a file, the next sync will contain baseline historical data catching up from your previous sync or the complete history if you haven’t synced a file before; subsequent syncs will contain changesets.
Turning the People file off
Disabling your sync
If your sync is already disabled, you can enable it again with these instructions. But, before you re-enable your sync, you should clear the previous sync files from your data warehouse bucket first. See Pausing and resuming your sync for more information.
- Go to Data & Integrations > Integrations and select Azure Blob Storage.
- Click Disable Sync.
Manage your configuration
You can change settings for a bucket, if your path changes or you need to swap keys for security purposes.
- Go to Data & Integrations > Integrations and select Azure Blob Storage.
- Click Manage Configuration for your bucket.
- Make your changes. No matter your changes, you must input your Blob SAS URL.
- Click Update Configuration. Subsequent syncs will use your new configuration.
Update sync schema version
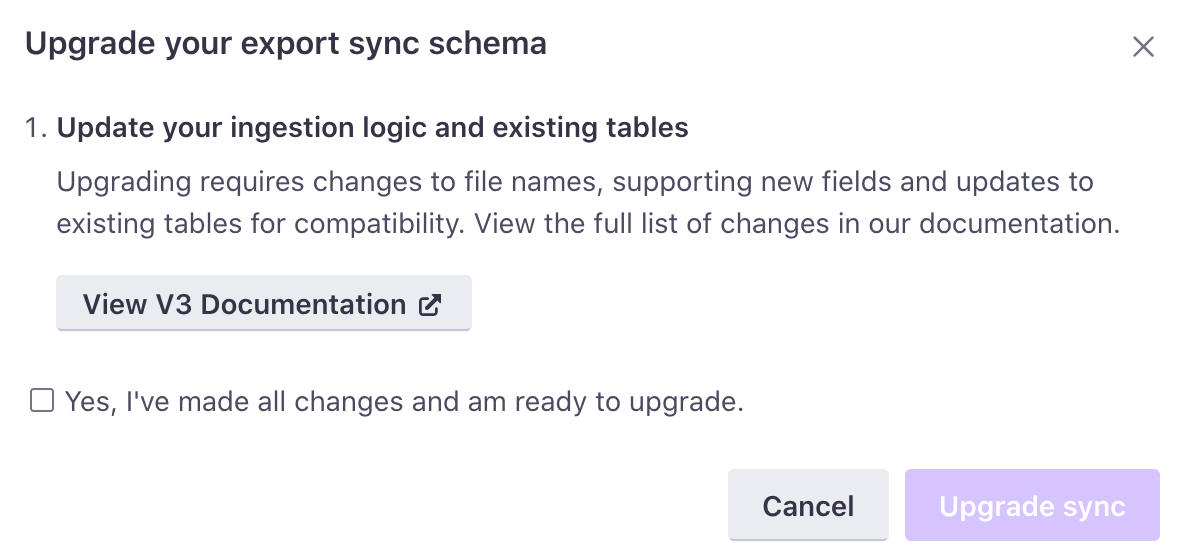
Before you prepare to update your data warehouse sync version, see the changelog. You’ll need to update schemas to upgrade to the latest version (v7).
When updating from v1 to a later version, you must:
- Update ingestion logic to accept the new file name format:
<name>_v<x>_<workspace_id>_<sequence>.parquet - Delete existing rows in your Subjects and Outputs tables. When you update, we send all of your Subjects and Outputs data from the beginning of your history using the new file schema.
- Go to Data & Integrations > Integrations and select Azure Blob Storage.
- Click Upgrade Schema Version.
- Follow the instructions to make sure that your ingestion logic is updated accordingly.
- Confirm that you’ve made the appropriate pages and click Upgrade sync. The next sync uses the updated schema version.
Parquet file schemas
This section describes the different kinds of files you can export from our Database-out integrations. Many schemas include an internal_customer_id—this is the cio_idAn identifier for a person that is automatically generated by Customer.io and cannot be changed. This identifier provides a complete, unbroken record of a person across changes to their other identifiers (id, email, phone, etc).. You can use it to resolve a profile associated with a subject, delivery, etc.
These schemas represent the latest versions available. Check out our changelog for information about earlier versions.
Deliveries
Deliveries are individual email, in-app, push, SMS, slack, and webhook records sent from your workspace. The first deliveries export file includes baseline historical data. Subsequent files contain rows for data that changed since the last export.
| Field name | Type | Required | Description |
|---|---|---|---|
workspace_id | integer | ✅ | The ID of the Customer.io workspace associated with the delivery record. |
delivery_id | string | ✅ | The ID of the delivery record. |
internal_customer_id | string | — | The cio_id of the person in question. Use the people parquet file to resolve this ID to an external customer_id or email address. |
subject_id | string | — | If the delivery was created as part of a Campaign or API Triggered Broadcast workflow, this is the ID for the path the person went through in the workflow. Note: This value refers to, and is the same as, the subject_name in the subjects table. |
event_id | string | — | If the delivery was created as part of an event-triggered Campaign, this is the ID for the unique event that triggered the workflow. Note that this is a foreign key for the subjects table, and not the metrics table. |
delivery_type | string | ✅ | The type of delivery. Accepted values: email · webhook · sms · slack · push · in_app · line · inbox · whatsapp · live_notification |
campaign_id | integer | — | If the delivery was created as part of a Campaign or API Triggered Broadcast workflow, this is the ID for the Campaign or API Triggered Broadcast. |
action_id | integer | — | If the delivery was created as part of a Campaign or API Triggered Broadcast workflow, this is the ID for the unique workflow item that caused the delivery to be created. |
newsletter_id | integer | — | If the delivery was created as part of a Newsletter, this is the unique ID of that Newsletter. |
content_id | integer | — | If the delivery was created as part of a Newsletter split test, this is the unique ID of the Newsletter variant. |
trigger_id | integer | — | If the delivery was created as part of an API Triggered Broadcast, this is the unique trigger ID associated with the API call that triggered the broadcast. |
created_at | datetime | ✅ | The timestamp the delivery was created at. |
transactional_message_id | integer | — | If the delivery occurred as a part of a transactional message, this is the unique identifier for the API call that triggered the message. |
seq_num | integer | ✅ | A monotonically increasing number indicating relative recency for each record: the larger the number, the more recent the record. |
internal_object_id | string | — | For object- or relationship-triggered campaigns, the internal ID of the object that triggered the delivery. Use the objects parquet file to resolve this ID to the external object_id (the ID you see in the Customer.io UI). Null for deliveries not triggered by an object. |
object_type_id | integer | — | For object- or relationship-triggered campaigns, the ID of the object type that triggered the delivery. Use the object_types parquet file to resolve this ID to the object type name. Null for deliveries not triggered by an object. |
Troubleshooting
I get a 403 error in Customer.io
This means that your Shared Access Signature URL doesn’t grant Customer.io permission to access your Azure blob store. Make sure that your Access policy or Shared access signature grant read, add, create, write, and list permissions. If not, you may need to edit your Access policy or generate a new SAS URL and paste it into Customer.io to fix the issue.
I can’t extend my SAS URL’s expiry date
By default, you Microsoft Azure doesn’t allow a Shared Access Signature (SAS) more than 1 week or 365 days in the future, depending on the signing method you use. You must create an Access policy that allows you to create tokens with a longer expiration period.
In general, we suggest that you create an Access policy as a way to both extend the life of your SAS token and as a method for revoking your SAS token later if you decide to turn off this integration.
To create an Access policy, right click your blob container in Microsoft Azure and go to Access policy. Add a policy with the same permissions as your SAS token (read, add, create, write, and list permissions), and set an expiry date in the future.

